Djangoのアプリをデプロイするのは良いですが、大切なデータは守りたいですよね。
今日はPythonのウェブフレームワーク、Djangoで作成したアプリケーションのデータベース(PostgreSQL)のデータベースをバックアップする方法を紹介します。
データベースのバックアップ
通常データベースのバックアップには下記の様な方法があります。
- pg_dumpのコマンドを使ってダンプファイルを抽出する。
- Djangoについてくるsqlclear/sqlallのコマンドを使う。
- Djangoについてくるdumpdata/loaddataのコマンドをつかう。
正しくDjangoのデータのバックアップを取る
上記のやり方には不備があります。
これらの方法だと、メディアファイル、つまり、FileFiledを使ってアップロードされたデータはバックアップに含まれません。
更に、Python manage.py migrateのコマンドで作成されるテーブル、つまりはパーミッション、セッションはバックアップに含まれません。
ですので、今日紹介するライブラリを使って簡単に正しいバックアップを取るようにしましょう。
django-dbbackupをインストールする
では、django-dbbackupのライブラリをインストールします。
下記にリンクを付けるので参考にしてください。
https://pypi.org/project/django-dbbackup/
pip install django-dbbackup #おまけです。 pip freeze > requirements.txt
次にプロジェクトのsettings.pyファイルに下記の様にインストールしたアプリを追加します。
INSTALLED_APPS = (
...
'dbbackup', # django-dbbackup
)
DBBACKUP_STORAGE = 'django.core.files.storage.FileSystemStorage'
DBBACKUP_STORAGE_OPTIONS = {'location': '/my/backup/dir/'}
バックアップを置く場所は下記の様に指定してもOKです。
DBBACKUP_STORAGE = 'django.core.files.storage.FileSystemStorage'
DBBACKUP_STORAGE_OPTIONS = {'location': BASE_DIR/'dump'}
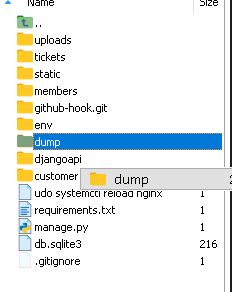
dumpフォルダーを作成しました。ここにbackupを置くようにします。
バックアップをとる
ではこれでOK。下記のコマンドでバックアップが取れるか試してみましょう。
python manage.py dbbackup

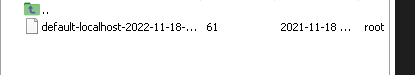
バックアップファイルができました!
バックアップからデータをリストア
では、試しにデータを変えてみます。レコードを一つ追加してみました。
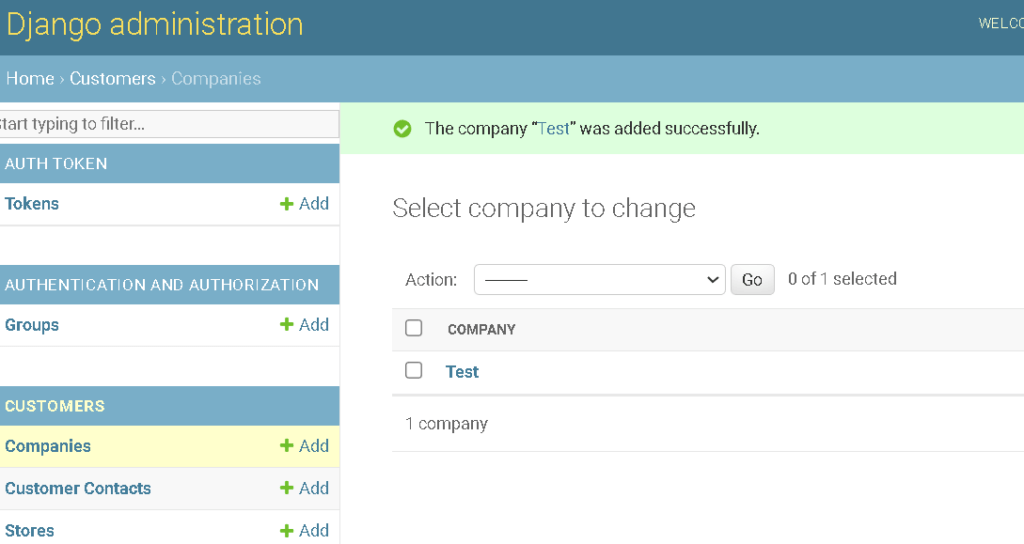
では、コマンドラインからバックアップを使ってデータをリストアしてみましょう。
このコマンドで一番新しいバックアップのファイルを使ってデータベースを上書きします。
python manage.py dbrestore

お見事!
データがバックアップの値に戻りました。
お疲れ様です。