
今日はPython初心者の方でもわかるウェブスクレイピングについて説明します。
ウェブスクレイピングとはウェブサイトにある情報をスクレイプ(剥ぎ取る)という事です。
例でいうと、過去の天気予報の情報をサイトからスクレイピングしたり、Amazonのサイトの商品の情報をスクレイピングしたりできます。
そのデータをどうするかはあなた次第ですが、このPythonの得意分野である自動化という力を発揮できる素晴らしいプロジェクトになります。
下準備
- Pythonの基本がわかっていること(1週間くらいの知識)
- HTMLの知識(タグ)
Beautiful Soupとは
Beautiful Soup(美しいスープ)はPythonのライブラリです。このライブラリを使ってウェフスクレイピングを行います。他にもウェブスクレイピングができるライブラリがありますが、一番お勧めがこのBeautiful Soupになります。
HTMLの基本を知っておく
ウェブサイトのスクレイピングをするにあたり、HTMLの構造を知らないとどの情報をスクレイピングしたいのか指示ができません。
まずは簡単なサイトでスクレイピングの練習をしましょう。
簡単なHTMLで練習
ローカルの環境にテスト用でHTMLを作成してスクレイピングの練習をします。
不要な人は飛ばしてください。
ではPythonとBeautifulSoupをセットアップしていきましょう。
環境のセットアップ
Pythonのライブラリをインストールする際にpip(パッケージマネージャー)を使用します。
このままパッケージをインストールしてしまうと、グローバルにパッケージがインストールされてしまいます。
個人で楽しむ分には問題ありませんが、今後、多数のプロジェクトを並行して作業するにあたり、仮想環境を準備するのが最適になります。
本題とはそれますが、それを学びたい方は下記の動画を見てください。
virtualenvのインストール
仮想環境を使いたい人はこちらのコマンドでインストールします。
pip install virtualenv

インストールができたら仮想環境を作成します。
virtualenv env #envはフォルダ名になります(自分で分かればなんでもよいですが)
仮想環境をアクティベートします。
#windows env\Scripts\activate #Linuxとmacはこれね。 source env/bin/activate
これでコマンドプロンプトの左側に環境名が表示されればOKです。

ここからPythonでインストールしたライブラリはenv内に格納されるのでアクティベートされたときのみPythonがアクセスできます。
BS4のインストール
BeautifulSoup4を略してbs4と言います。
何事もインストールする前にはちょっとだけでも公式ドキュメンテーションを見ておくものです。
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
ではこれをインストールしていきましょう。
pip install beautifulsoup4
インストールされました!
lxmlのインストール
BS4で作業するにあたり、HTMLのパーサー(読み込む役割)をするライブラリが必要になります。
LxmlはHTMLのパーサーのライブラリの一つで、お勧めなのでインストールしていきます。
pip install lxml #pip listのコマンドでインストールしたパッケージが一覧で見れます。
コードを書く
ではやっと下準備が整ったのでコードを書いていきましょう。
私は、テキストエディタはVSCodeを使います。皆さんが使っているものをどうぞ。
では下記のようにコードを書いていきます。
# インストールしたライブラリのインポート
from bs4 import BeautifulSoup
# ファイルの指定、r = 読込のみ
#html_fileは変数
with open('index.html', mode="r",encoding="utf-8") as html_file:
content = html_file.read()
print(content)
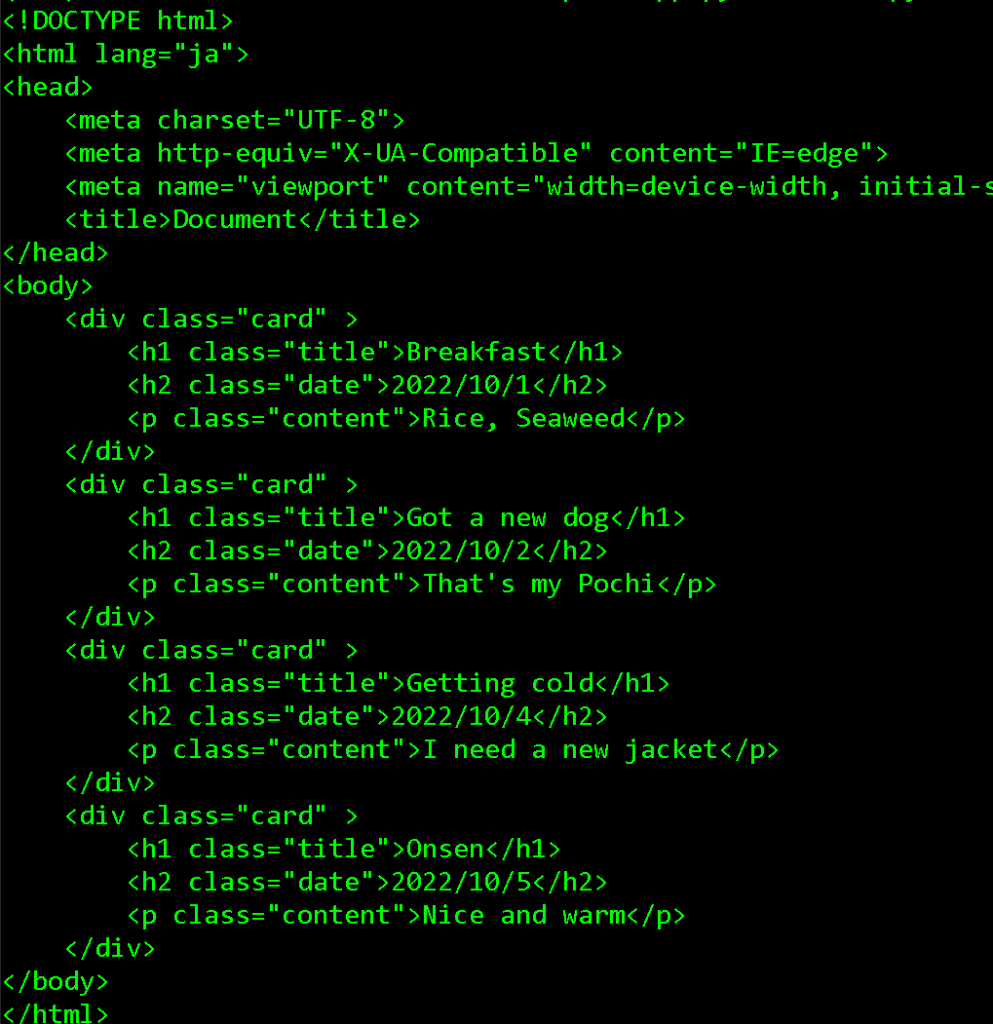
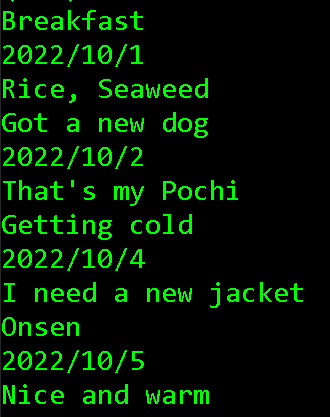
同じディレクトリにindex.htmlで下記の中身のファイルを作成します。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div class="card" >
<h1 class="title">Breakfast</h1>
<h2 class="date">2022/10/1</h2>
<p class="content">Rice, Seaweed</p>
</div>
<div class="card" >
<h1 class="title">Got a new dog</h1>
<h2 class="date">2022/10/2</h2>
<p class="content">That's my Pochi</p>
</div>
<div class="card" >
<h1 class="title">Getting cold</h1>
<h2 class="date">2022/10/4</h2>
<p class="content">I need a new jacket</p>
</div>
<div class="card" >
<h1 class="title">Onsen</h1>
<h2 class="date">2022/10/5</h2>
<p class="content">Nice and warm</p>
</div>
</body>
</html>
ではコマンドプロンプトからPythonファイルを実行します。
python main.py
見事!HtmlのファイルがPythonから読み込まれました。
しかし、このままだとHTMLタグも入って見づらいのでbeautifulSoupのPrettifyを使ってキレイにしましょう。
from bs4 import BeautifulSoup
with open('index.html', mode="r",encoding="utf-8") as html_file:
content = html_file.read()
soup = BeautifulSoup(content, 'lxml')
print(soup.prettify())
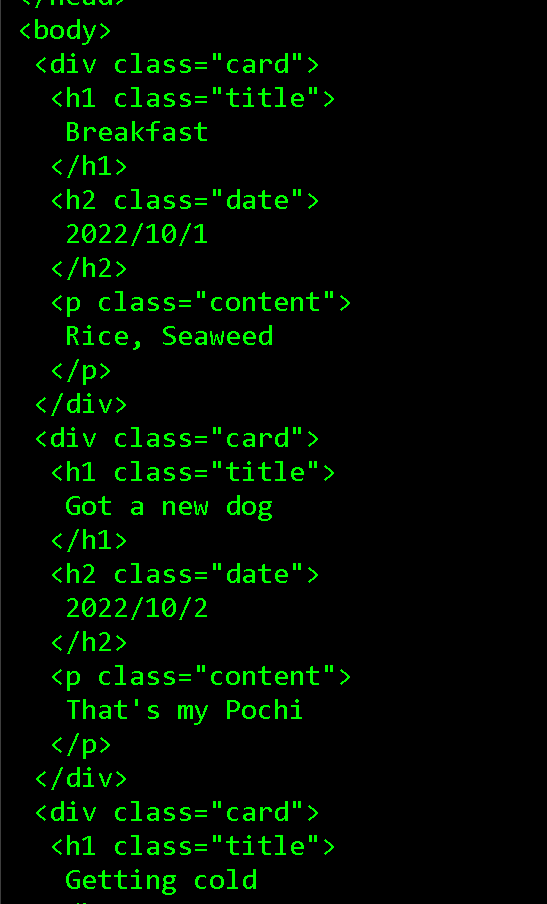
さっきよりキレイになりました!
HTMLタグで絞り込む
.find
ではH1タグのHTMLだけをスクレイピングしたい場合はこのようにします。
soup.findメソッドを使い、タグを指定してあげます。
from bs4 import BeautifulSoup
with open('index.html', mode="r",encoding="utf-8") as html_file:
content = html_file.read()
soup = BeautifulSoup(content, 'lxml')
tags = soup.find('h1')
print(tags)

.fins_all
これだと最初のh1タグしかスクレイピングされませんね。
では、すべてのh1タグをスクレイピングするようにしましょう。
findのメソッドをfind_allに変えてみましょう。
from bs4 import BeautifulSoup
with open('index.html', mode="r",encoding="utf-8") as html_file:
content = html_file.read()
soup = BeautifulSoup(content, 'lxml')
tags = soup.find_all('h1')
print(tags)

すべてのh1タグがスクレイピングされました!
では最初に作成したHTMLのタグを使ってセットでスクレイピングしてみましょう。
for ループを使います。
from bs4 import BeautifulSoup
with open('index.html', mode="r",encoding="utf-8") as html_file:
content = html_file.read()
soup = BeautifulSoup(content, 'lxml')
blog_html_tags = soup.find_all('h1')
for blog in blog_html_tags:
print(blog.text)
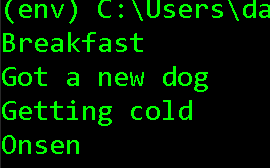
.textのメソッドを使い、タグの中身だけをループさせることができました。
グループをループさせる
それぞれのデータは記事、もしくはカードのようにひとまとまりになっていますね。
ではこれを見つけ出して、ループさせましょう。
その中にある、タイトルや日付をまとめてスクレイピングできるようにします。
from bs4 import BeautifulSoup
with open('index.html', mode="r",encoding="utf-8") as html_file:
content = html_file.read()
soup = BeautifulSoup(content, 'lxml')
# divタグでcardのクラスを絞る
blog_cards = soup.find_all('div', class_='card')
for blog in blog_cards:
blog_title = blog.h1.text
blog_date = blog.h2.text
blog_content = blog.p.text
print(blog_title)
print(blog_date)
print(blog_content)
ブラウザのデベロッパーツール
では実際のウェブサイトに行きデベロッパーツールを開きます。
クロームならF12のショートカットでオープンできます。
ここで実際のWebページのHTMLの構成を見ることができます。
詳しい説明は次回の記事で説明します。
お疲れ様でした。