LangChainとは
LangChainは2022年にリリースされたライブラリになるのでChatGPTに聞いても教えてくれません。(ChatGPTは2021年までのデータまでしか把握していません。)
以下に、なぜLangChainがChatGPTを使用するうえで重要なライブラリになるかを説明します。
LangChainは、自然言語処理(NLP)のためのライブラリとツールセットです。LangChainは、様々なNLPタスクにおいて効率的かつ柔軟な開発を支援するために設計されています。
LangChainの主な機能とコンポーネントには以下があります:
- ConversationalRetrievalChain: 対話型の情報検索システムを構築するためのフレームワークです。複数の文脈情報を保持しながら、ユーザーの質問に対して適切な回答を返すことができます。
- RetrievalQA: 質問応答(QA)システムを構築するためのモジュールです。事前に用意された文書コーパスからの情報検索と、質問と回答のマッチングを行います。
- ChatOpenAI: OpenAIのGPTモデルを使用した対話モデルです。ユーザーの入力に基づいて自然な応答を生成することができます。
- DocumentLoader: テキストデータの読み込みと準備を行うためのツールです。テキストファイルやディレクトリからデータをロードし、モデルの学習や検索のために準備します。
- OpenAIEmbeddings: OpenAIの埋め込みモデルを使用してテキストのベクトル表現を生成するためのモジュールです。テキストデータを数値表現に変換することで、検索や比較などのタスクを効率的に実行できます。
- VectorstoreIndexCreator: テキストデータのインデックスを作成するためのツールです。ベクトル表現を使用してデータを効率的に検索するためのインデックスを作成します。
- VectorStoreIndexWrapper: ベクトルデータをインデックスに結び付けるためのラッパーモジュールです。ベクトルデータの検索や類似度の計算などを実行するためのインターフェースを提供します。
LangChainはこれらのコンポーネントを組み合わせて使用することで、自然言語処理のさまざまなタスクを効率的に実行することができます。
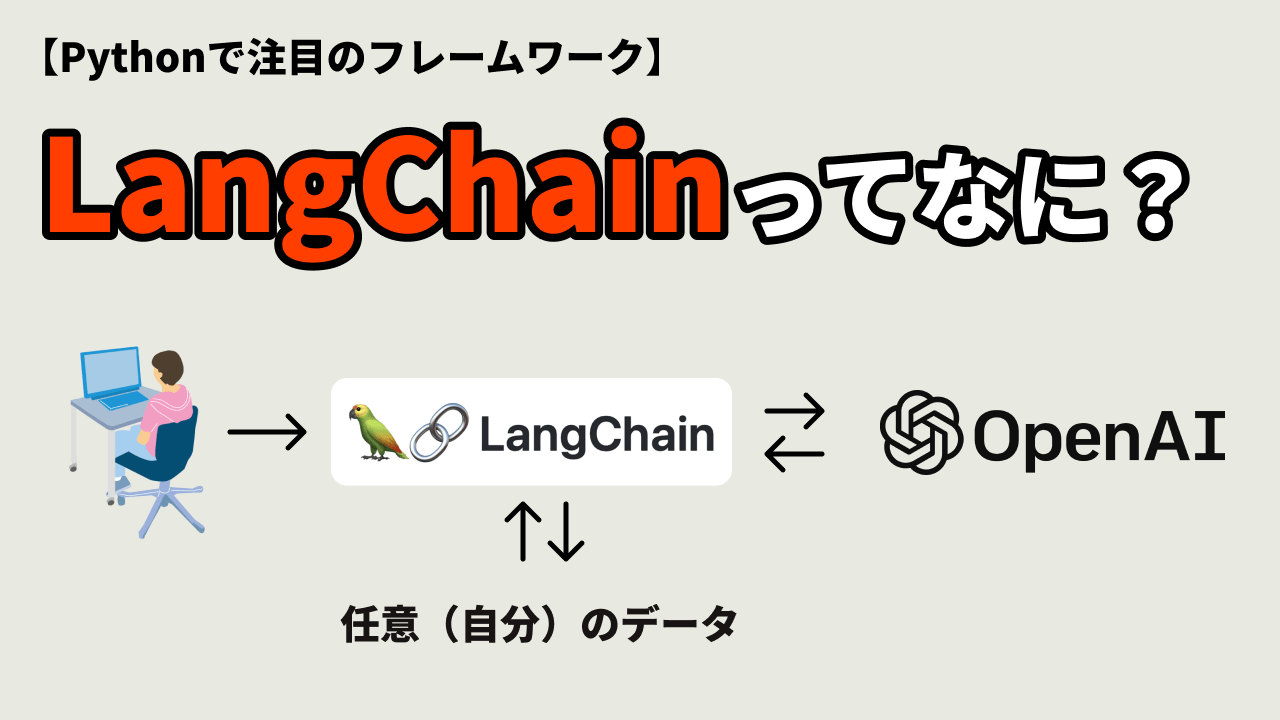
つまり、我々が提供するデータからChatGPTを使ってユーザーと対話側のコミュニケーションが取れるアプリケーションが作成できるライブラリになります。
PythonとJavaScript
LangChainはPythonとJavaScriptの両方で使用することができます。PythonライブラリはこのGitHubリポを参照してください。JavaScriptGitHubリポはこちらから確認してください。
LangChainが正しい回答をクエリする流れ
LangChainにおけるベクターデータベースから質問の回答に近い答えをクエリする一般的な流れは次のようになります:
- データの準備とベクトル化: LangChainでは、まず質問に関連するデータを準備し、ベクトル表現に変換します。これには、テキストデータのロード、テキストの前処理、OpenAIEmbeddingsなどの埋め込みモデルを使用したテキストのベクトル化が含まれます。
- インデックスの作成: 準備されたデータのベクトルを使用して、データベースのインデックスを作成します。VectorstoreIndexCreatorモジュールを使用して、データのベクトル表現を効率的に検索するためのインデックスを作成します。
- ConversationalRetrievalChainの構築: ConversationalRetrievalChainは、質問に対する回答を検索するためのフレームワークです。LangChainでは、このフレームワークを構築し、必要なパラメータや検索方法を指定します。例えば、ChatOpenAIモデルを使用して回答を生成し、VectorStoreIndexWrapperを使用してベクターデータベースを検索します。
- 質問と回答の探索: ユーザーからの質問が入力されると、ConversationalRetrievalChainを使用して質問と過去の対話履歴を組み合わせて回答を探索します。ConversationalRetrievalChainは、ベクターデータベースの検索や回答生成を行い、最適な回答を返します。
- 回答の返信と対話履歴の更新: 検索された回答をユーザーに返信し、対話履歴を更新します。このようにして、ユーザーの質問と回答の対話を継続します。
この流れに従ってLangChainを使用することで、ベクターデータベースから質問に近い回答を効率的にクエリすることができます。LangChainの機能とコンポーネントは、この流れをサポートするために設計されており、柔軟性と効率性を提供します。
つまり。。。
上記までの内容をもっと分かりやすくまとめます。
通常はユーザーがChatGPTに直接アクセスする流れになります。
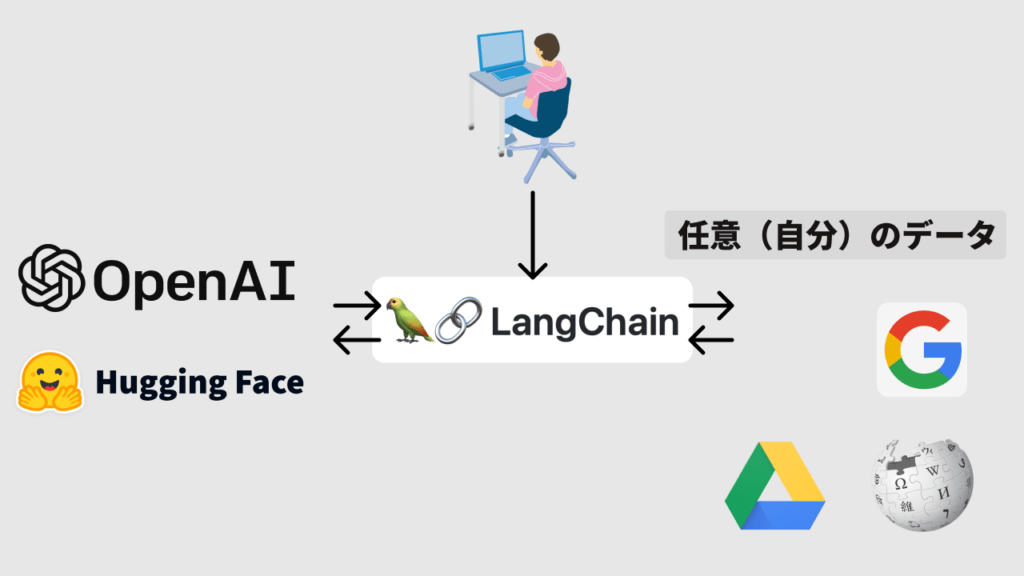
しかしLangChainを使用することでChatGPTなどの言語モデルを介して、自分のデータを参照させることができます。
なぜこれがゲームチェンジャーかというと、このLangChainを使用することでほとんどすべての企業でベネフィットを得ることができるようになります。例えば社内でのドキュメントの検索、ユーザーがマニュアルやデータを参照する際のプラットフォームの作成など、使用方法は無限です。またGoogleに接続することでリアルタイムの情報(天気やニュースなど)を理解させることも可能になります。
LangChainのインストール(Python)
今回の記事ではPythonのライブラリに絞って解説をしていきます。
pip install langchain
これでLangChainの最低限必要なライブラリがインストールされます。LangChainの強みは、さまざまなモデルプロバイダやデータストアなどと統合する際に生じます。ただし、そのために必要なモジュールはデフォルトではインストールされません。
一般的なLLMプロバイダに必要なモジュールをインストールするには、次のコマンドを実行してください。
pip install langchain[llms] pip install langchain[all] #zsh pip install 'langchain[all]'
環境の設定
LangChainを使用する場合、通常は1つ以上のモデルプロバイダ、データストア、APIなどとの統合が必要となります。この例では、OpenAIのモデルAPIを使用します。
まず、OpenAIのPythonパッケージをインストールします。
pip install openai
APIへのアクセスにはAPIキーが必要です。アカウントを作成し、こちらにアクセスすることでAPIキーを取得できます。キーを取得したら、環境変数として設定するために次のコマンドを実行します。
export OPENAI_API_KEY="..."
環境変数を設定したくない場合は、OpenAIのLLMクラスを初期化する際にopenai_api_keyという名前のパラメーターを直接渡すこともできます。
from langchain.llms import OpenAI llm = OpenAI(openai_api_key="...")
アプリケーションの構築
さて、言語モデルアプリケーションの構築を始めましょう。LangChainは、言語モデルアプリケーションの構築に使用できる多くのモジュールを提供しています。モジュールは単体で簡単なアプリケーションで使用することもできますし、より複雑なユースケースではモジュールを組み合わせることもできます。
LLMs
言語モデルから予測を取得する
LangChainの基本的な構築ブロックはLLM(Language Model)であり、テキストを受け取り、さらなるテキストを生成します。
例として、企業の説明に基づいて企業名を生成するアプリケーションを構築しているとしましょう。これを行うために、OpenAIモデルのラッパーを初期化する必要があります。この場合、出力をよりランダムにしたいので、モデルを高いtemperatureで初期化します。
from langchain.llms import OpenAI llm = OpenAI(temperature=0.9)
そして、テキストを渡して予測を取得できます。
llm.predict("What would be a good company name for a company that makes colorful socks?")
# >> Feetful of Fun
チャットモデル
チャットモデルは、対話型言語モデルです。チャットモデルは言語モデルを内部で使用しますが、公開するインターフェースは少し異なります。通常の「テキストの入力とテキストの出力」のAPIではなく、複数のメッセージを入力として受け取り、応答としてメッセージを返します。
チャットモデルには、1つ以上のメッセージをチャットモデルに渡すことでチャットの補完を取得できます。応答はメッセージとして返されます。LangChainで現在サポートされているメッセージの種類はAIMessage、HumanMessage、SystemMessage、ChatMessageであり、ChatMessageは任意の役割パラメータを受け取ります。ほとんどの場合、HumanMessage、AIMessage、SystemMessageの3つのメッセージを使用します。
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI(temperature=0)
chat.predict_messages([HumanMessage(content="Translate this sentence from English to French. I love programming.")])
# >> AIMessage(content="J'aime programmer.", additional_kwargs={})
チャットモデルが通常のLLMとどのように異なるかを理解することは役立ちますが、通常は同じように扱えると便利です。LangChainでは、チャットモデルと同様にLLMとやり取りするためのインターフェースも提供されています。これは、predictインターフェースを介してアクセスできます。
chat.predict("Translate this sentence from English to French. I love programming.")
# >> J'aime programmer
プロンプトテンプレート
プロンプトテンプレート(Prompt Templates)は、ほとんどのLLMアプリケーションではユーザーの入力を直接LLMに渡さず、通常はユーザーの入力を追加の文脈情報を提供するより大きなテキスト、つまりプロンプトテンプレートに追加します。
先ほどの例では、モデルに渡したテキストには企業名を生成するための指示が含まれていました。アプリケーションでは、ユーザーが企業や製品の説明を提供するだけで、モデルに指示を与える必要はないと便利です。
Chains
チェーン(Chains)を使用すると、モデル、プロンプトテンプレート、他のチェーンなど、複数のプリミティブをリンク(またはチェーン)して組み合わせることができます。
チェーンは、LangChainフレームワークにおいて、異なるプリミティブを連結して組み合わせるための仕組みです。これにより、モデルとテンプレートを結びつけて特定のタスクを実行することができます。
たとえば、モデルとプロンプトテンプレートを組み合わせて、特定のテキスト生成タスクを実行するチェーンを作成することができます。また、より複雑なアプリケーションを構築するために、複数のチェーンを結合して使用することもできます。
チェーンは、LangChainの柔軟性と拡張性を高める重要な要素であり、異なるプリミティブを組み合わせることで、さまざまなタスクに対応できるようになります。
Agents
エージェント(Agents)は、入力に基づいて動的にアクションを選択する必要がある複雑なワークフローを処理するために使用されます。
エージェントは、言語モデルを使用して、どのアクションを取るか、どの順序で取るかを決定します。エージェントはツールにアクセス権があり、ツールを選択し、実行し、出力を観察して最終的な回答を導き出すまで、繰り返し動作します。
エージェントを読み込むには、次の要素を選択する必要があります:
LLM/Chatモデル:エージェントのバックエンドとなる言語モデルです。 ツール:特定のタスクを実行するための関数です。例えば、Google検索、データベース検索、Python REPL、他のチェーンなどが含まれます。事前定義されたツールとその仕様については、ツールのドキュメントを参照してください。 エージェント名:サポートされているエージェントクラスを参照する文字列です。エージェントクラスは、言語モデルがどのアクションを選択するかを決定するために使用するプロンプトによって主にパラメータ化されます。
Memory
これまで見てきたチェーンとエージェントは、ステートレスでしたが、多くのアプリケーションでは過去の相互作用を参照する必要があります。たとえば、チャットボットの場合、新しいメッセージを過去のメッセージの文脈で理解できるようにしたいです。
Memoryモジュールは、アプリケーションの状態を維持する方法を提供します。基本的なMemoryインターフェースはシンプルで、最新の実行の入力と出力に基づいて状態を更新し、保存された状態を使用して次の入力を変更(または文脈化)することができます。
いくつかの組み込みのメモリシステムがあります。その中でも最もシンプルなものは、直近の数個の入力/出力を現在の入力の前に追加するバッファメモリです。
まとめ
ほとんど公式ドキュメンテーションの翻訳だけになってしまいました。次回以降、実際にコードを書いてLangChainを使用する方法を紹介していきます。
お疲れ様でした。