【Python】ChatGPTとLangChain使って自分のデータから検索させる
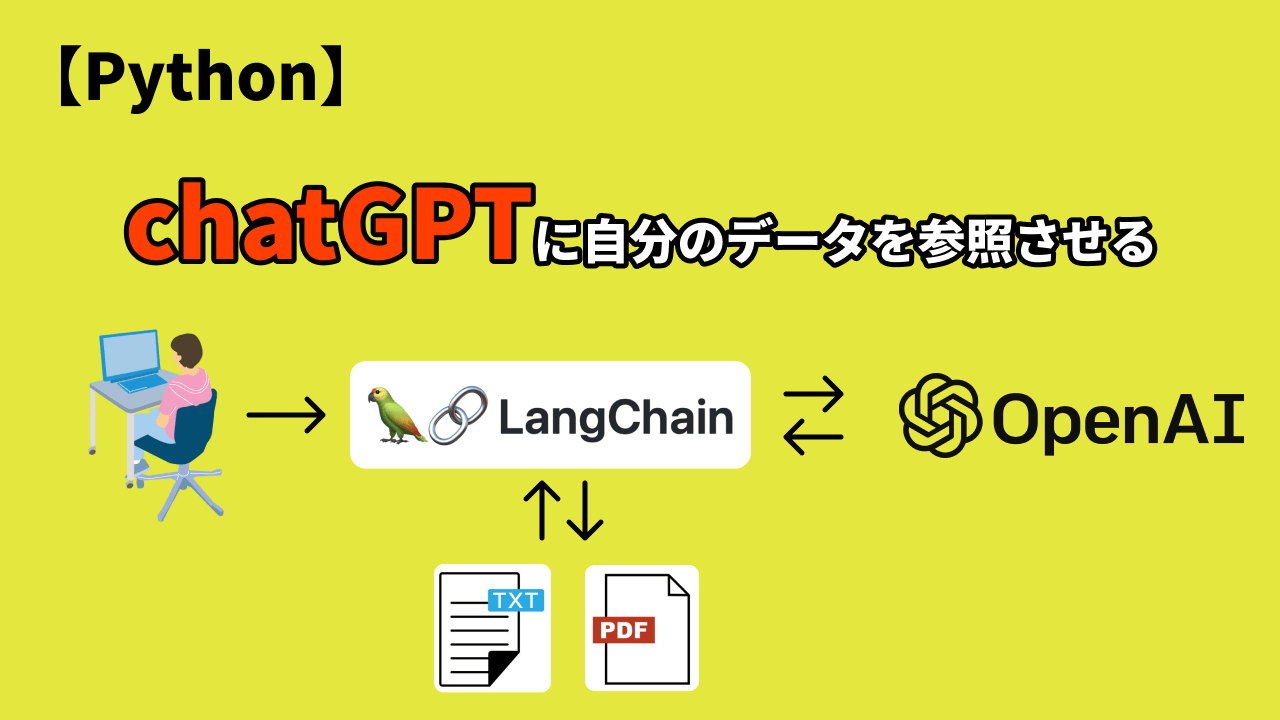
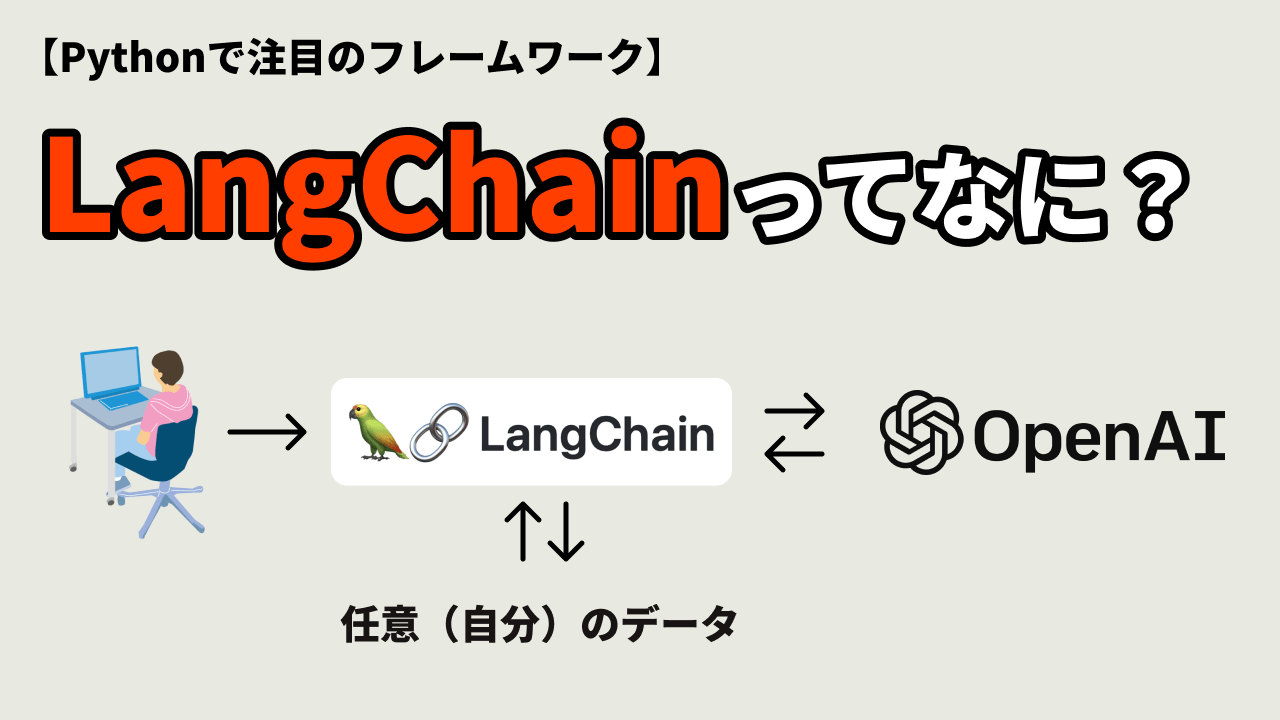
目的 ユーザーがChatGPTに質問をするとOpenAIが持っているデータベースを参照して回答してくれます。しかしこのデータは2021年までしか保存されていないため、それ以降のデータは質問しても回答してくれません。例として2022年にリリースされたLangChainのフレームワークのことをChatGPTに質問すると下記の画像のように知らないと回答されます。 また、自分でアップロードしたデータを参照させたい場合もファイルのサイズに制限があります。 しかし、今日紹介する、PyhotnフレームワークのLangChainとChatGPTを使用することで自分で指定したデータからクエリさせることが可能になります。例として同じLangChainについて質問をさせました。そしてChatGPTにLangChainのドキュメンテーション(英語)を読み取りさせています。ChatGPTに読ませたファイルはGitHubのdataディレクトリ内にあります。 このテクノロジーはアメリカの大企業のQ&Aやカスタマーサポートなどで使われ始めている機能で、すぐに当たり前の技術になってくるでしょう。(私がアメリカにいるので日本ではどれくらい復旧しているかは確認していません。) 完成したコードはGitHubから見てください。 先に準備(理解)しておくこと 今回のプロジェクトにはOpenAIのAPIキーが必要になります。このキーを取得するにはクレジットカードを登録する必要があります。テストくらいのリクエストのみであればジュース代だと思って使うのもありだと思います。※自己責任で進めてください。 chromaDBはオプショナルですが、ChatGPTに入力した記録を残しChatGPTがその会話をデータとして参照できるようにします。 LangChainは今回の主役になるフレームワークです。 プロジェクトのセットアップ では下記のコマンドでGitHubからリポジトリをクローンしましょう。 以下に手順を詳しく説明します: APIキーを貼り付ける constantsCOPY.pyのファイル名からCOPYを取り除き、constants.pyにします。次にChatGPTのAPIキーを貼り付けます。 ファイルを実行する ではdataディレクトリにchatGPTに読ませたいデータを入れておきます。.txtファイル、PDFファイル、CSVファイル、JSONファイルなどが読み込み可能です。 次に下記のコマンドでpyファイルを実行します。 では次にコードを詳しく説明します。 メソッドのインポート リポジトリになるように下記に必要なメソッドとモジュールをインポートします。 ChromaDBのコンフィグ この行は、モデルをディスクに保存して再利用するための設定を行っています。 PERSIST は、モデルをディスクに保存して再利用するかどうかを制御するためのブール値の変数です。現在は False に設定されていますので、モデルの永続化は無効になっています。 PERSIST を True に設定すると、モデルがディスクに保存され、同じデータに対して繰り返しクエリを実行する場合に、モデルを再作成する必要がありません。これにより、処理時間を節約できます。 ただし、モデルをディスクに保存すると、ディスク容量の使用量が増えることに注意する必要があります。また、ディスク上の保存データの管理や更新も考慮する必要があります。 クエリの作成 このコードは、query 変数を使用してインデックスを再利用するかどうかを判断し、その結果に応じてインデックスを作成します。 まず、query を None に初期化します。次に、条件 len(sys.argv) > 1 を使用して、コマンドライン引数の数が1つ以上あるかどうかをチェックします。もし引数が存在する場合、sys.argv[1] の値が query に代入されます。 その後、PERSIST が True かつ “persist” という名前のディレクトリが存在する場合、インデックスを再利用していることを示すメッセージが表示されます。Chroma クラスのインスタンスである vectorstore を作成し、VectorStoreIndexWrapper … Read more