皆さん、お疲れ様です。
今日は、Ubutnu ServerのISOファイルを使って、VirtualBoxにインストールする作業を説明します。
Ubutnu のデスクトップバージョンも同じやり方でできますし、他のLinuxも同じ方法なので是非試してみてください。
特にお金のかかるサーバーをレンタルする前のテストにはもってこいです!
今日の環境
- Windows10(VirtualBoxのホストPC、OSで何でもOKです。)
- ホストPCのメモリが8G以上(理想は16G以上)
- VirtualBoxがインストールされた状態
- UbutnuServer22.04
VirtualBoxってなに?
VirtualBoxはOracle社が提供している仮想マシンのアプリケーションのことです。MicrosoftではHyper-Vという同じような仮想マシンを提供しています。他に、有名なものではVMWareというものもあります。
動画ではVirtualBox(以下、略してVB)のインストールから説明しているのでご覧ください。
ISOファイルをダウンロード
Ubuntuの公式サイトからUbuntu ServerのISOファイルをダウンロードしておきます。
https://ubuntu.com/download/server
VBインスタンスを作成
Instanceは事例、という意味ですが、プログラマーの世界では、プロジェクトの意味合いに近いものになります。
では、早速Newのボタンを押して新しいインスタンス(プロジェクト)を作成します。これが各OSがインストールされる仮想マシンになるわけですね。
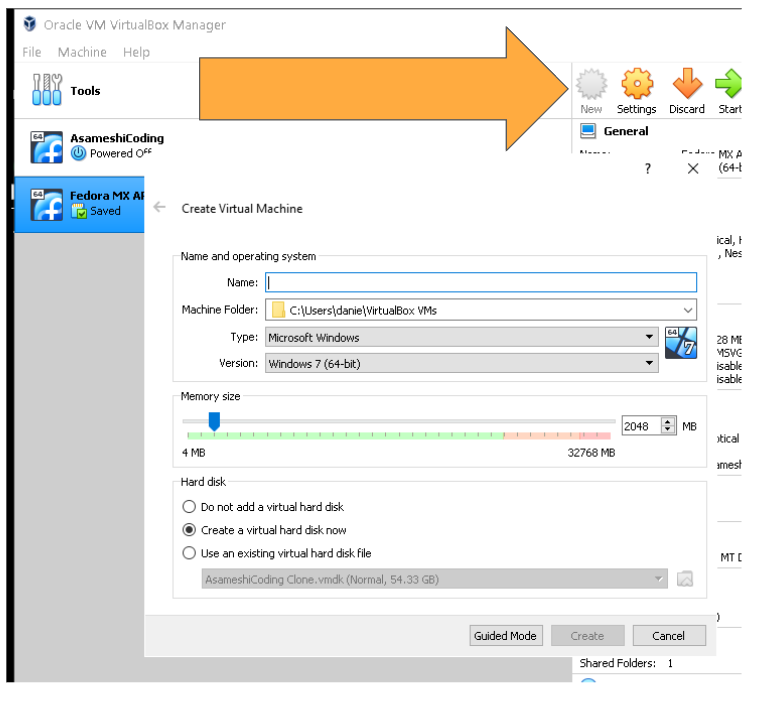
で、マシン名と、メモリのサイズを指定していきます。サーバーだけならデスクトップよりもメモリは食わないので4Gあれば足りるかな?私は8Gに設定しておきました。これは後から調整できるので色々試してください。
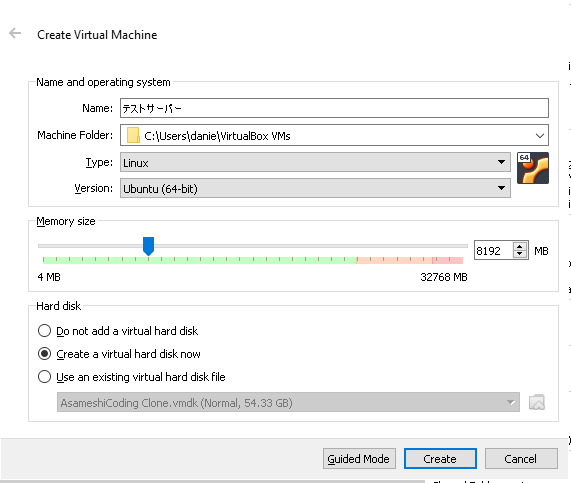
で、Createをクリック。
ファイルサイズを指定します。
使用目的にもよりますが、使うと思う分のハードディスクを割り当ててください。
Hard Disk File Typeは、仮想マシンのファイル端子のことです。他の人とシェアしないならどれでも構わないと思います。
私はVMDKを選びました、これならエキスポートした仮想マシンファイルをVirtualBox以外のアプリケーションにインポートすることができます。
Storage on physical hard diskはハードディスクの容量をどのように区切るかの設定です。
通常はDynamically allocatedでOKです。これは、指定した分を実際にハードディスクから削り取るのではなく、使った分だけダイナミックにホストPCから割り当てるという事になります。
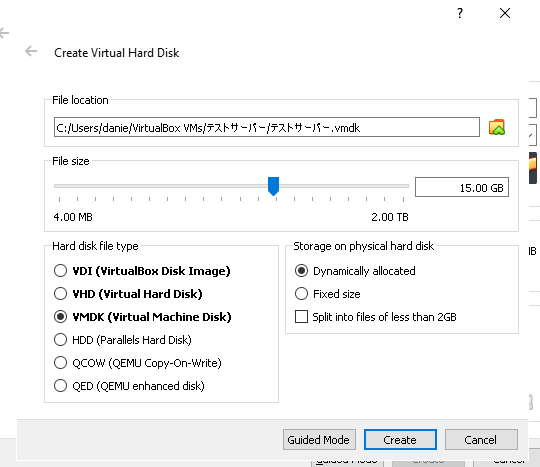
これで問題なければCreateを押します。
ネットワークの設定
では、インスタンスがハイライトされた状態でSettingsを押して詳細を確認します。
ネットワーク設定を見てみましょう。
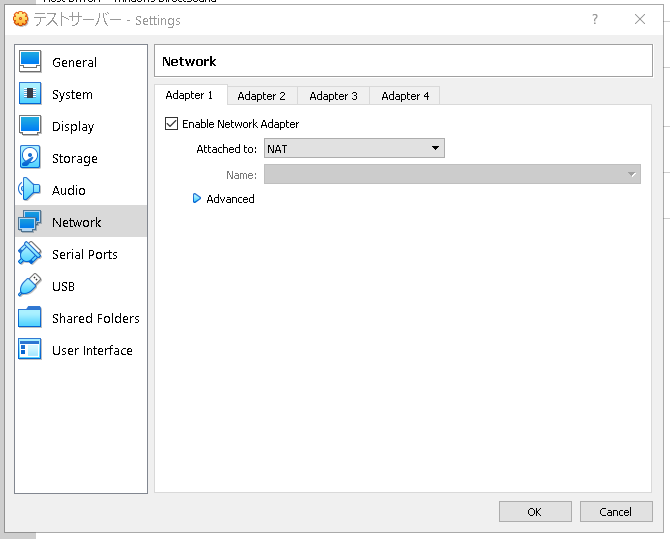
もし同じLANネットワークで使用したいのであればBrige Networkを使用しましょう。
その場合は、ホストPCが192.168.1.5とかなら、192168.5.16などの同じネットワークのIPが割り当てられます。
NATの場合はちょっと複雑になります。私の場合はとりあえずこのままでOKにしておきます。
インストールするOSを指定
ではStartボタンからマシンを起動しましょう。
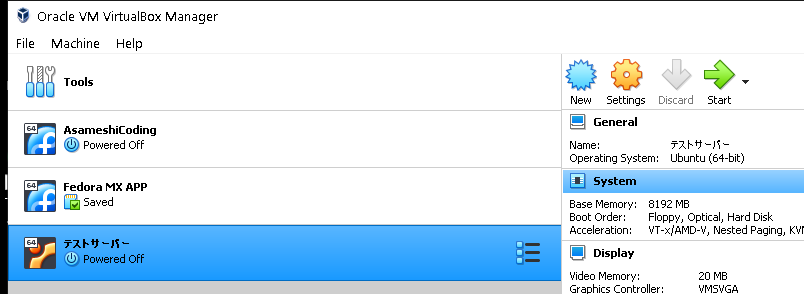
そうするとスタートアップに使用するででディスクを指定してくださいというメッセージが出ます。
フォルダのアイコンをクリックしましょう。
Addを押します。
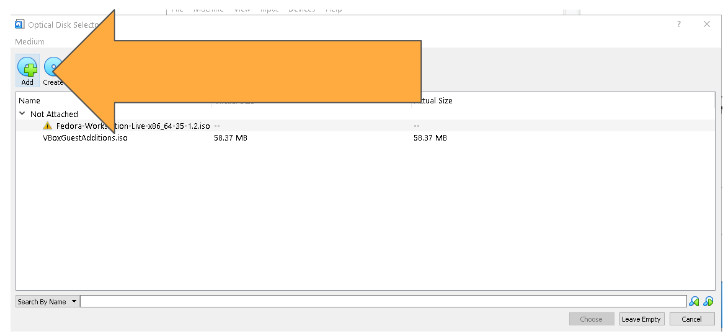
では、ダウンロードしておいたUbuntuサーバーのISOファイルを指定します。
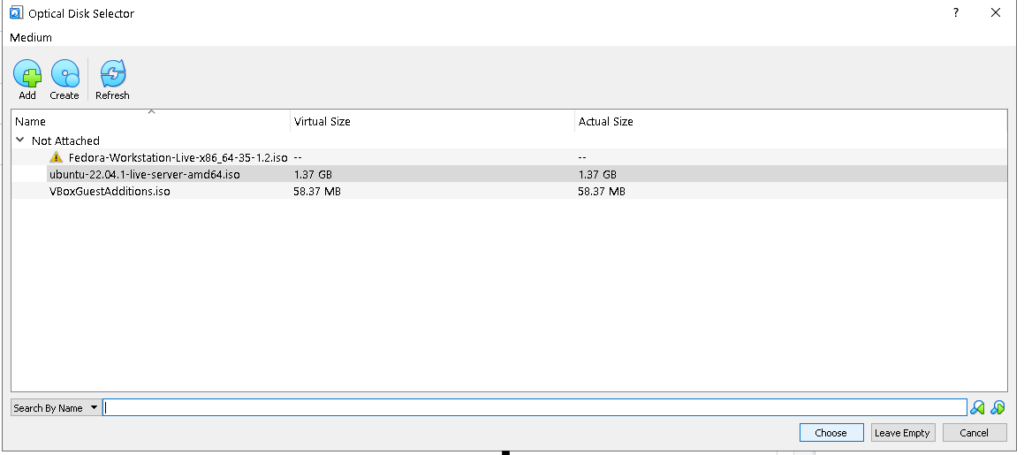
Chooseを押します。
ではStartを押してマシンを起動しましょう。
Ubuntuサーバーのインストール
ではインストールが始まるので言語選択の画面になるまで待ちます。
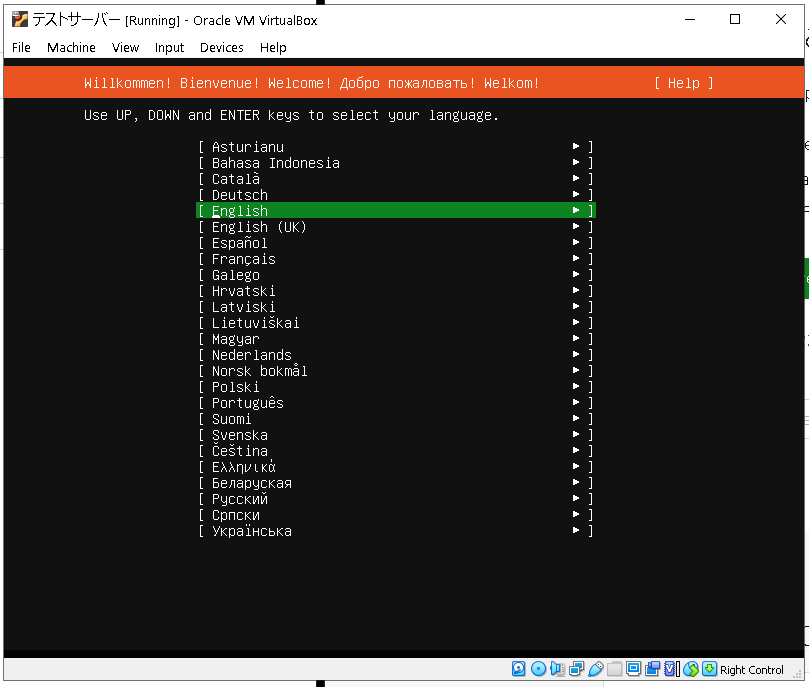
日本語がないので英語で進めていきます。私はプログラミングは全部英語で行っています。皆さんも同じ習慣をつけることをお勧めします。
ではEnglishがハイライトされた状態でエンターを押します。
キーボードの設定をします。
キーボードのタブボタンを使って上下にスクロールします。スクロールアップの場合はシフトを押しながらタブになります。LayoutをJapanese、VariantをJapaneseにしましょう。
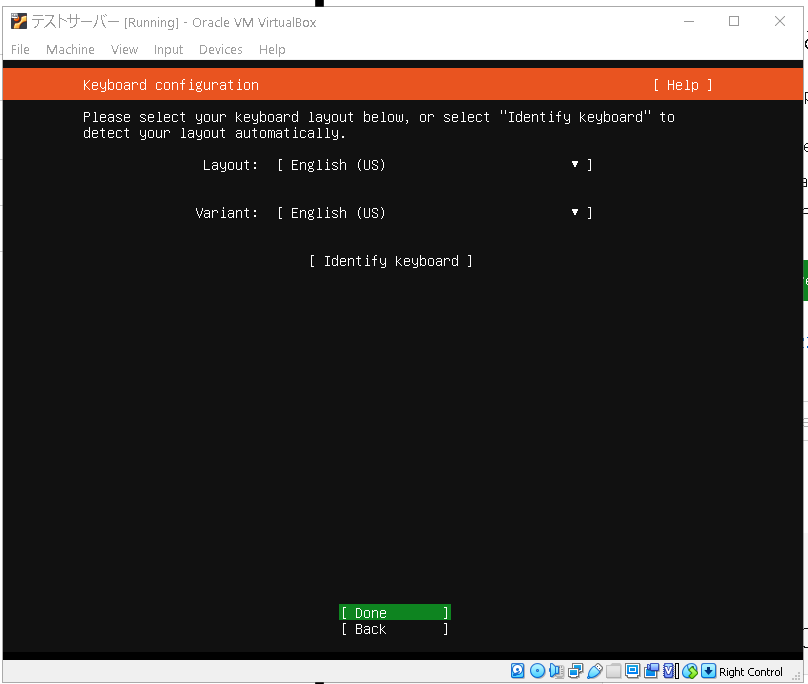
完了したらDoneを選択します。
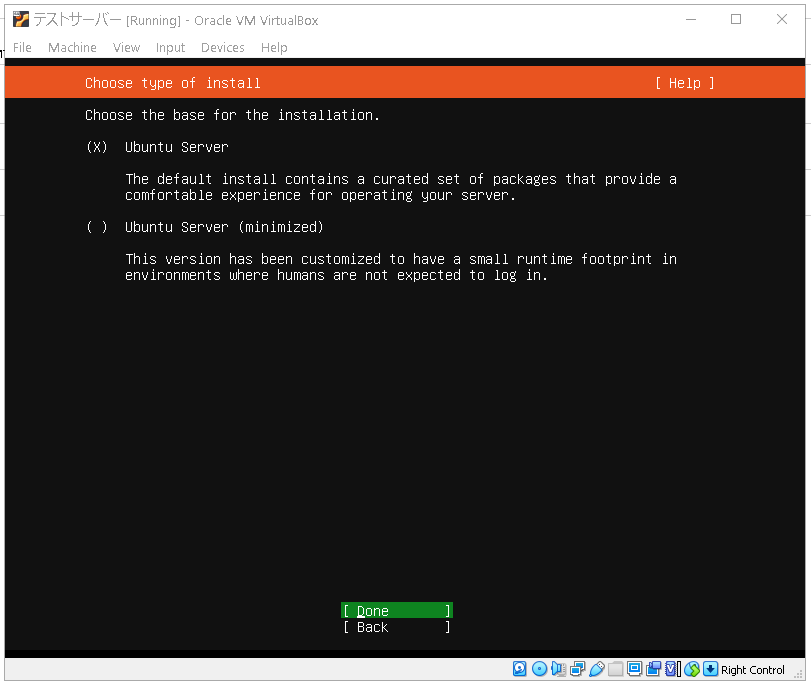
特にハードディスクに制限がない場合は通常版のサーバーをインストールしましょう。
minimizedバージョン(軽量版)をインストールしても後から変更できるのでどっちでもOKです。
選択したらDoneをクリックします。
ネットワークの設定をします。
これも後から変更できるのでそのままにしてDoneにしましょう。
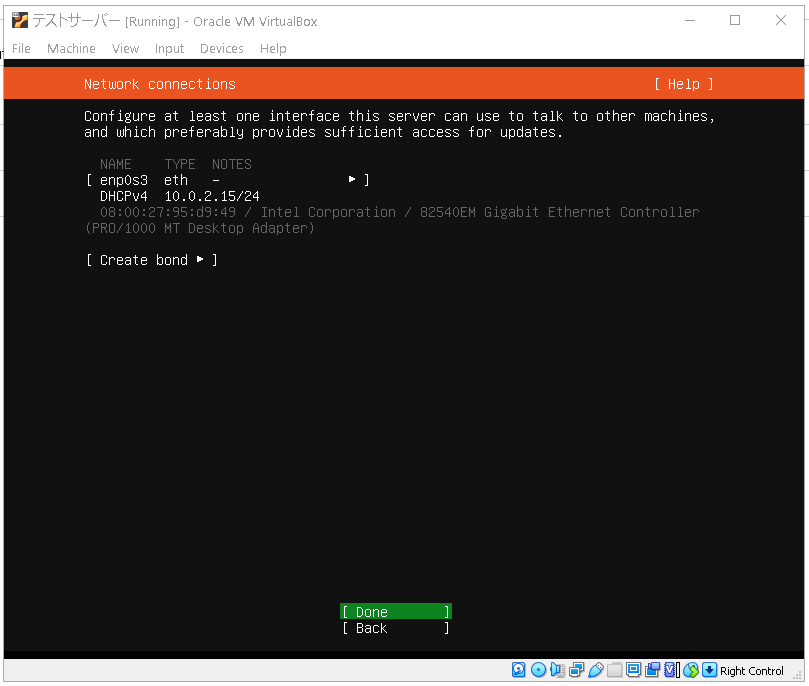
次のプロキシアドレスの設定も後から行うのでそのままdoneにします。
これもそのままDoneでOKです。
ストレージはヴァーチャルボックスで割り当てた分をUbuntuサーバーで使用できるようになっているのでデフォルトのまま次に進みましょう。
では全体のサマリーをみて問題がなさそうならdoneを押します。
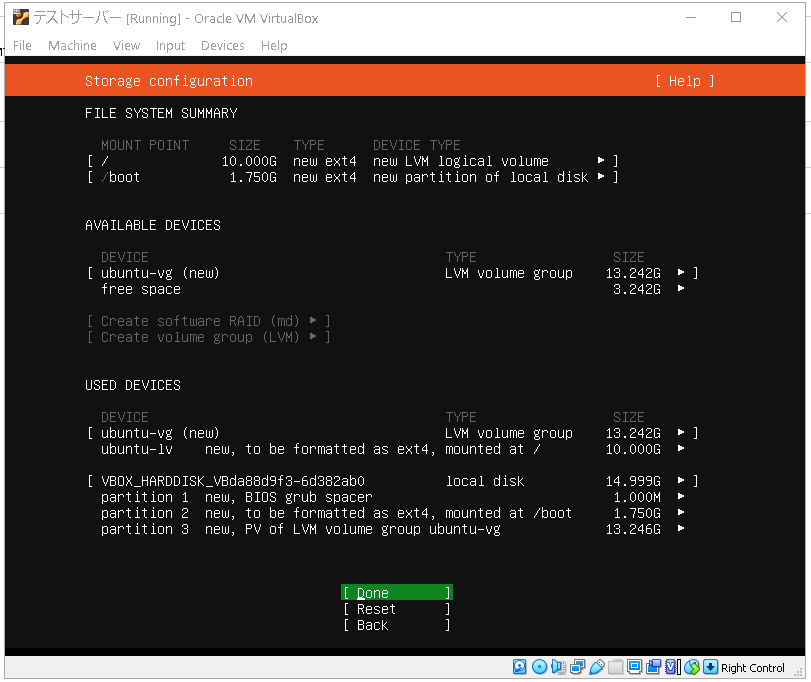
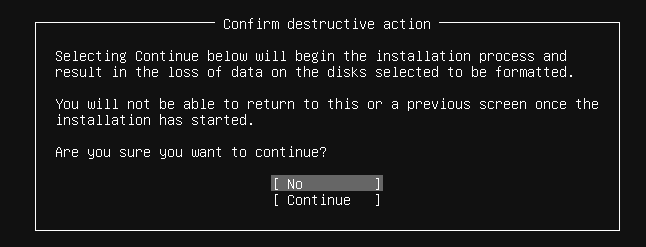
そうすると確認のメッセージが出るのでContinueを選択しエンター。
Ubutnuのユーザーを作成します。
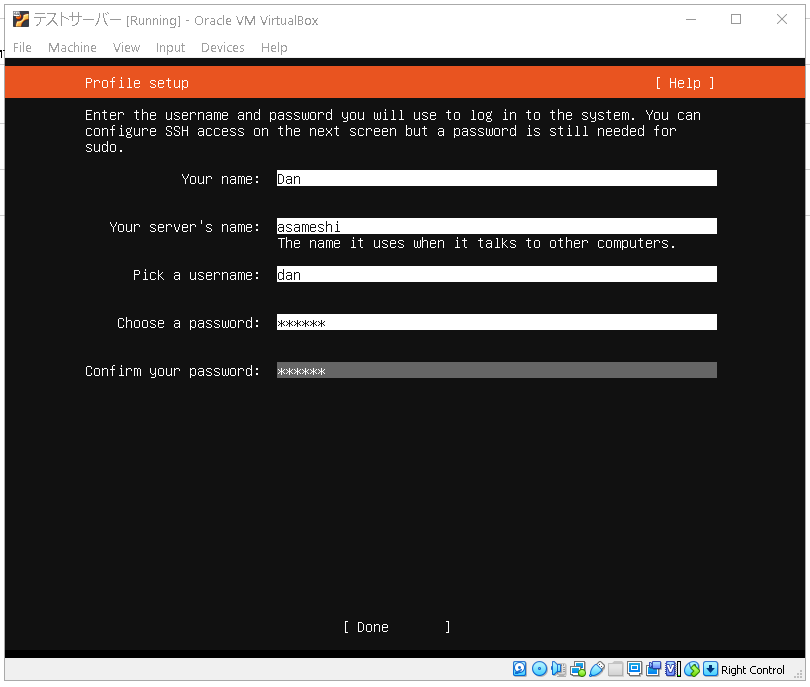
これはログインの際に使います。
こんな感じで適当に入力できたらDoneを押します。
次にオープンSSHサーバーをインストールするか聞かれます。
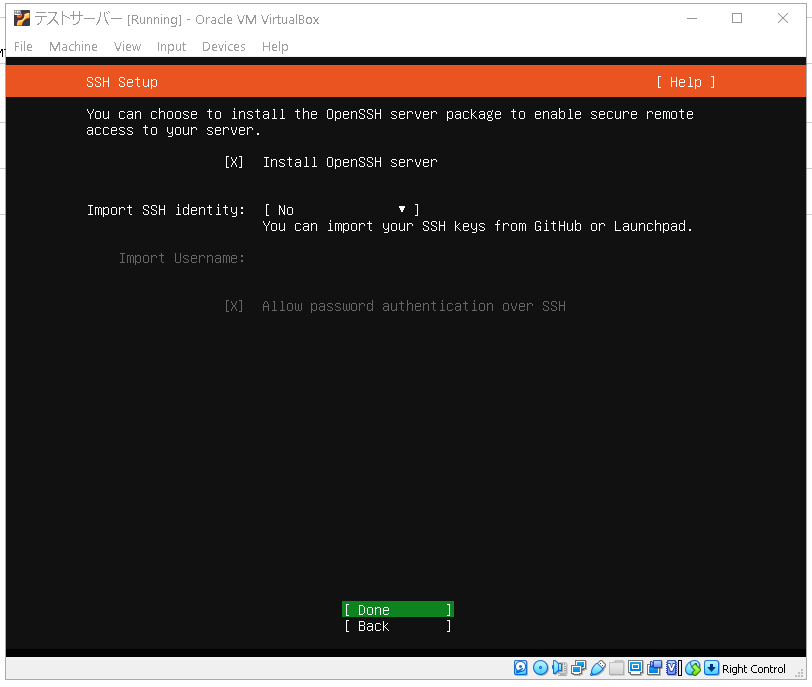
もしSSHの意味が分からない人は下記に説明の動画があるので見てみてください。
要約すると、ホスト側(ユーザー側)のPCのコマンドライン(シェル、コマンドプロンプト、ターミナル)からサーバー側のマシンにアクセスするためのツールになります。
これは必須の知識なので是非、練習してみましょう。
ですので、タブとエンターキーを使ってInstall Open SSHServerにチェックを入れてDoneを選択します。
次に他にインストールしたいアプリケーションがあれば選択してください。
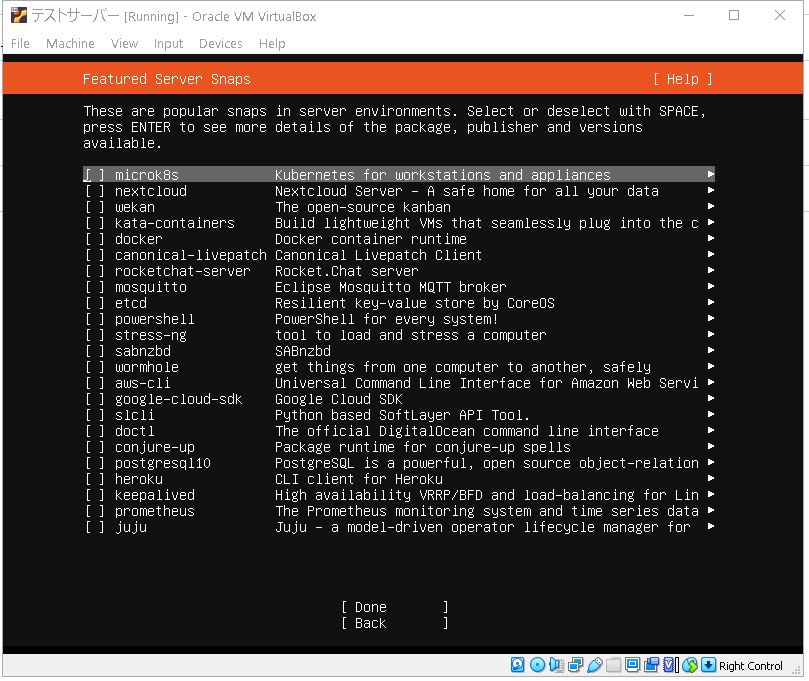
個人的にnextcloudのファイル管理アプリが楽しそうだと思いました。
とりあえず今回はスキップするのでそのままDoneを選択します。
インストールが始まります。
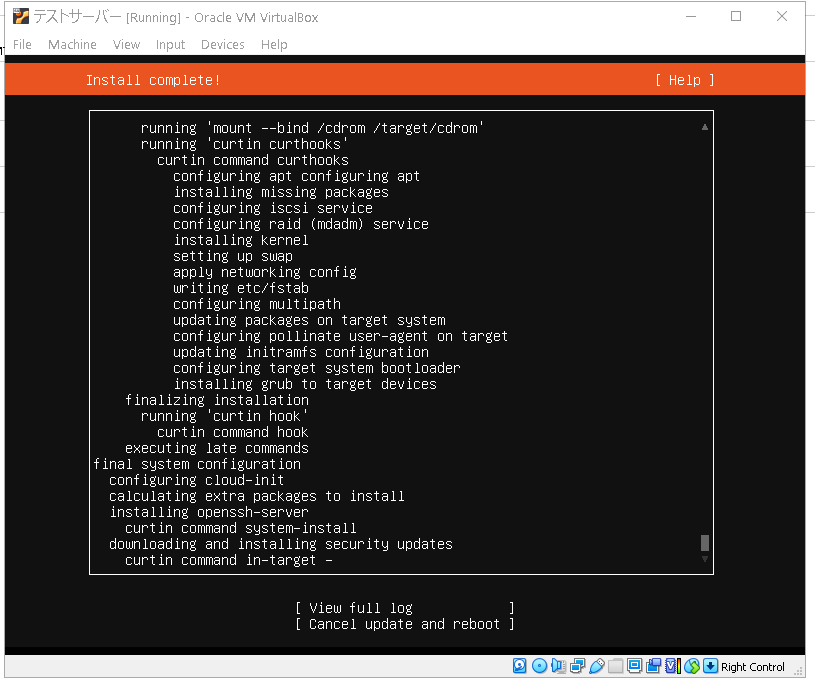
インストールが完了したら下のオプションからReboot Nowを選択してマシンを再起動します。
バーチャルボックス側ではインストール用のISOファイルは外れると思いますが、一応それを確認して、サーバーが起動できることを確認します。
サーバーを再起動
サーバーを再起動すると先ほど設定したパスワードを聞かれます。
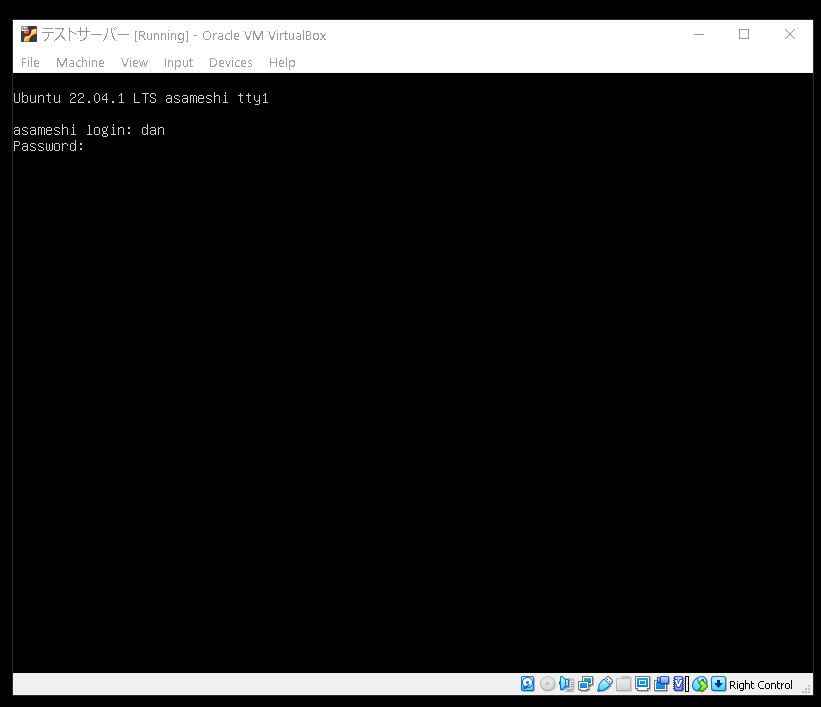
パスワードの部分は打っても何も動かないですが、入力されています。
ログイン情報を入力したらエンターを押します。
これでログインができました!
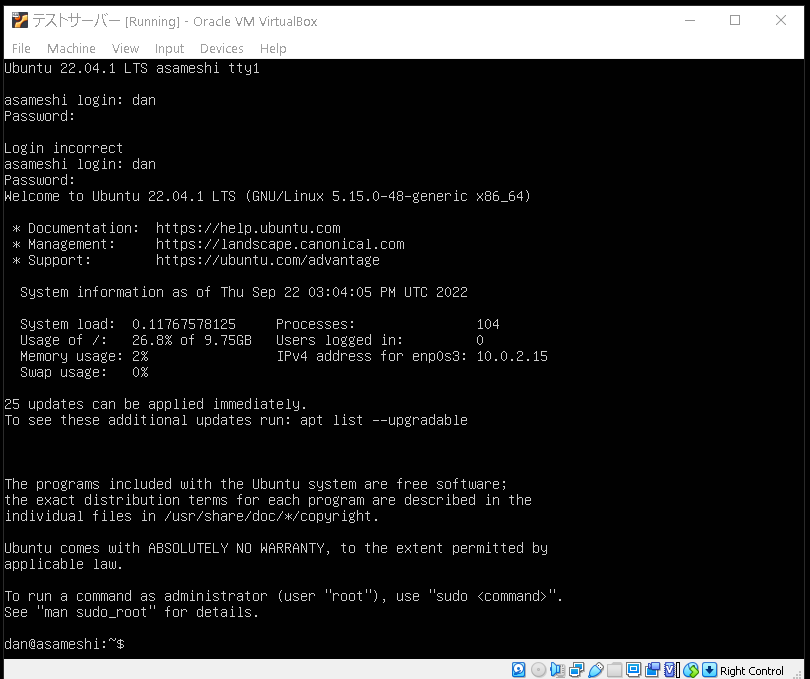
とりあえずUbuntu Serverがインストールできたので今日はこれでおしまいにします。
この後はサーバーの更新、初期設定をしたり、SSHで接続してWebサーバーを設定していきたいと思います。
良かったら他の記事も参考にしてください。
ではお疲れ様です。